阿布云
你所需要的,不仅仅是一个好用的代理。
用Python实现带随机梯度下降的线性回归

许多机器学习算法的核心是优化。优化算法用于在机器学习中为给定训练集找出合理的模型参数设置。机器学习最常见的优化算法是随机梯度下降(SGD:stochastic gradient descent)。
本教程将指导大家用 Python 实现随机梯度下降对线性回归算法的优化。通过本教程的学习,你将了解到:
-
如何用随机梯度下降估计线性回归系数
-
如何对多元线性回归做预测
-
如何用带随机梯度下降的线性回归算法对新数据做预测
说明
本文将对线性回归、随即梯度下降方法以及本教程所使用的葡萄酒品质数据集做一个集中阐释。
多元线性回归
线性回归是一种用于预测真实值的方法。让人困惑的是,这些需要预测真实值的问题被称为回归问题(regression problems)。
线性回归是一种用直线对输入输出值进行建模的方法。在超过二维的空间里,这条直线被想象成一个平面或者超平面(hyperplane)。预测即是通过对输入值的组合对输出值进行预判。
y = b0 + b1 * x1 + b2 * x2 + ...
系数 (b) 用于对每个输入属性 (x) 进行加权,而学习算法的目的正是寻找一组能导出好的预测值 (y) 的系数。这些系数可以使用随机梯度下降的方法找到。
随机梯度下降
梯度下降(Gradient Descent)是遵循成本函数的梯度来最小化一个函数的过程。这个过程涉及到对成本形式以及其衍生形式的认知,使得我们可以从已知的给定点朝既定方向移动。比如向下朝最小值移动。
在机器学习中,我们可以利用随机梯度下降的方法来最小化训练模型中的误差,即每次迭代时完成一次评估和更新。
这种优化算法的工作原理是模型每看到一个训练实例,就对其作出预测,并重复迭代该过程到一定的次数。这个流程可以用于找出能导致训练数据最小误差的模型的系数。用机器学习的术语来讲,就是每次迭代过程都用如下等式更新系数(b)。
b = b - learning_rate * error * x
其中 b 是系数或者被优化的权重,learing_rate 需手动设定(如 0.01),error 是取决于权重的训练数据模型的预测误差,x 是输入值。
葡萄酒品质数据集
开发了具有梯度下降的线性回归算法之后,我们可以将其运用到一个关于葡萄酒品质的数据集当中。这个数据集囊括了 4898 种白葡萄酒的测量标准,包括酸度和 ph 值。目的是用这些客观标准来预测葡萄酒的品质,分为 0 到 10 级。
下表给出了 5 个数据样本。
7,0.27,0.36,20.7,0.045,45,170,1.001,3,0.45,8.8,6
6.3,0.3,0.34,1.6,0.049,14,132,0.994,3.3,0.49,9.5,6
8.1,0.28,0.4,6.9,0.05,30,97,0.9951,3.26,0.44,10.1,6
7.2,0.23,0.32,8.5,0.058,47,186,0.9956,3.19,0.4,9.9,6
7.2,0.23,0.32,8.5,0.058,47,186,0.9956,3.19,0.4,9.9,6
所有数据需归一化为 0-1 之间的值。每种属性标准单位不同,因而有不同的缩放尺度。通过预测该归一化数据集的平均值(零规则算法),达到了 0.148 的基准方均根差(RMSE)。
该数据集详情请参阅 UCI Machine Learning Repository:http://archive.ics.uci.edu/ml/datasets/Wine+Quality
下载该数据集并将其保存到当前工作目录,文件名为 winequality-white.csv。(注意:文件开头的头信息需去除,用作分隔符的 『;』 需改为符合 CSV 格式的 『,』。)
教程
本教程分为三个部分:
1. 预测
2. 估计系数
3. 葡萄酒品质预测
这将能让你了解在你自己的预测建模问题上实现和应用带有随机梯度下降的线性回归的基础。
1. 预测
首先建立一个用于预测的函数。这将用于对随机梯度下降的候选系数的评估,且模型确定之后也需要这个函数。我们会在测试集或者新的数据上用该函数来进行预测。
函数 predict() 如下所示,用于预测给定了一组系数的行的输出值。
第一个系数始终为截距,也称为偏差或 b0,因其相对独立且不与特定的输入值相关。
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return yhat
我们可以用一个小的数据集对这个函数进行测试。
x, y
1, 1
2, 3
4, 3
3, 2
5, 5
下图是一小部分数据:
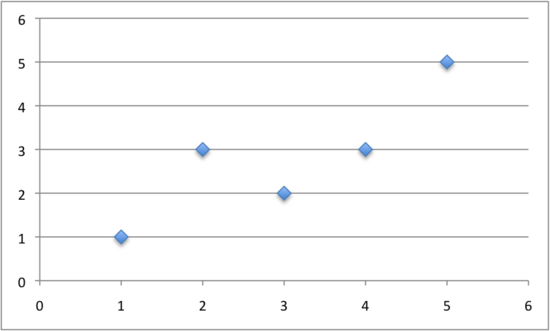
线性回归的部分转换数据
我们也可用之前准备好的系数为这个数据集做预测。predict() 函数测试如下。
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return yhat
dataset = [[1, 1], [2, 3], [4, 3], [3, 2], [5, 5]]
coef = [0.4, 0.8]
for row in dataset:
yhat = predict(row, coef)
print("Expected=%.3f, Predicted=%.3f" % (row[-1], yhat))
单个输入值 (x) 和两个系数(b0 和 b1)。用于建模该问题的预测方程为:
y = b0 + b1 * x
或者,手动选择特定系数:
y = 0.4 + 0.8 * x
运行此函数,我们将得到一个相当接近预测值的输出值(y)。
Expected=1.000, Predicted=1.200
Expected=3.000, Predicted=2.000
Expected=3.000, Predicted=3.600
Expected=2.000, Predicted=2.800
Expected=5.000, Predicted=4.400
现在我们可以用随机梯度下降来优化我们的系数值了。
2. 估计系数
我们可以使用随机梯度下降来为我们的训练数据估计系数值。随机阶梯下降需要两个设定参数:
-
学习率(Learning Rate):用于限制每次更新时被修正的系数的数量。
-
Epochs:更新系数的同时运行训练集的次数。
这两个值和数据集都是函数的参数。我们的这个函数将执行三个遍历循环:
1. 单次 epoch 循环
2. 单次 epoch 中训练集中的每行循环
3. 单次 epoch 中每个系数循环并为每一行更新它
可以看到,每次 epoch,我们都会更新数据集里每行的系数。系数的更新是基于模型生成的误差。该误差被算作候选系数的预测值和预期输出值之间的差。
error = prediction - expected
有一个系数用于加权每一个输入属性,这些属性将以连续的方式进行更新,比如
b1(t+1) = b1(t) - learning_rate * error(t) * x1(t)
列表开始的特殊系数,也被称为截距(intercept)或偏差(bias),也以类似的方式更新,但因其不与特定输入值相关,所以无输入值。
b0(t+1) = b0(t) - learning_rate * error(t)
现在我们把所有东西组合在一起。coefficients_sgd() 函数正是用随机梯度下降来计算一个训练集的系数值,下面即是该函数:
# Estimate linear regression coefficients using stochastic gradient descent
def coefficients_sgd(train, l_rate, n_epoch):
coef = [0.0 for i in range(len(train[0]))]
for epoch in range(n_epoch):
sum_error = 0
for row in train:
yhat = predict(row, coef)
error = yhat - row[-1]
sum_error += error**2
coef[0] = coef[0] - l_rate * error
for i in range(len(row)-1):
coef[i + 1] = coef[i + 1] - l_rate * error * row[i]
print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))
return coef
此外,我们追踪每个 epoch 的方差(正值)总和从而在循环之后得到一个好的结果。
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return yhat
# Estimate linear regression coefficients using stochastic gradient descent
def coefficients_sgd(train, l_rate, n_epoch):
coef = [0.0 for i in range(len(train[0]))]
for epoch in range(n_epoch):
sum_error = 0
for row in train:
yhat = predict(row, coef)
error = yhat - row[-1]
sum_error += error**2
coef[0] = coef[0] - l_rate * error
for i in range(len(row)-1):
coef[i + 1] = coef[i + 1] - l_rate * error * row[i]
print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))
return coef
# Calculate coefficients
dataset = [[1, 1], [2, 3], [4, 3], [3, 2], [5, 5]]
l_rate = 0.001
n_epoch = 50
coef = coefficients_sgd(dataset, l_rate, n_epoch)
print(coef)
我们用 0.001 的学习速率训练该模型 50 次,即把整个训练数据集的系数曝光 50 次。运行一个 epoch 系统就将该次循环中的和方差(sum squared error)和以及最终系数集合 print 一次:
>epoch=45, lrate=0.001, error=2.650
>epoch=46, lrate=0.001, error=2.627
>epoch=47, lrate=0.001, error=2.607
>epoch=48, lrate=0.001, error=2.589
>epoch=49, lrate=0.001, error=2.573
[0.22998234937311363, 0.8017220304137576]
可以看到误差是如何在历次 epoch 中持续降低的。或许我们可以增加训练次数(epoch)或者每个 epoch 中的系数总量(调高学习速率)。
尝试一下看你能得到什么结果。
现在,我们将这个算法用到实际的数据当中。
3. 葡萄酒品质预测
我们将使用随机阶梯下降的方法为葡萄酒品质数据集训练一个线性回归模型。本示例假定一个名为 winequality—white.csv 的 csv 文件副本已经存在于当前工作目录。
首先加载该数据集,将字符串转换成数字,并将输出列从字符串转换成数值 0 和 1. 这个过程是通过辅助函数 load_csv()、str_column_to_float() 以及 dataset_minmax() 和 normalize_dataset() 来分别实现的。
我们将通过 K 次交叉验证来预估得到的学习模型在未知数据上的表现。这就意味着我们将创建并评估 K 个模型并预估这 K 个模型的平均误差。辅助函数 cross_validation_split()、rmse_metric() 和 evaluate_algorithm() 用于求导根均方差以及评估每一个生成的模型。
我们用之前创建的函数 predict()、coefficients_sgd() 以及 linear_regression_sgd() 来训练模型。完整代码如下:
# Linear Regression With Stochastic Gradient Descent for Wine Quality
from random import seed
from random import randrange
from csv import reader
from math import sqrt
# Load a CSV file
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# Convert string column to float
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# Find the min and max values for each column
def dataset_minmax(dataset):
minmax = list()
for i in range(len(dataset[0])):
col_values = [row[i] for row in dataset]
value_min = min(col_values)
value_max = max(col_values)
minmax.append([value_min, value_max])
return minmax
# Rescale dataset columns to the range 0-1
def normalize_dataset(dataset, minmax):
for row in dataset:
for i in range(len(row)):
row[i] = (row[i] - minmax[i][0]) / (minmax[i][1] - minmax[i][0])
# Split a dataset into k folds
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = len(dataset) / n_folds
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# Calculate root mean squared error
def rmse_metric(actual, predicted):
sum_error = 0.0
for i in range(len(actual)):
prediction_error = predicted[i] - actual[i]
sum_error += (prediction_error ** 2)
mean_error = sum_error / float(len(actual))
return sqrt(mean_error)
# Evaluate an algorithm using a cross validation split
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in fold]
rmse = rmse_metric(actual, predicted)
scores.append(rmse)
return scores
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return yhat
# Estimate linear regression coefficients using stochastic gradient descent
def coefficients_sgd(train, l_rate, n_epoch):
coef = [0.0 for i in range(len(train[0]))]
for epoch in range(n_epoch):
for row in train:
yhat = predict(row, coef)
error = yhat - row[-1]
coef[0] = coef[0] - l_rate * error
for i in range(len(row)-1):
coef[i + 1] = coef[i + 1] - l_rate * error * row[i]
# print(l_rate, n_epoch, error)
return coef
# Linear Regression Algorithm With Stochastic Gradient Descent
def linear_regression_sgd(train, test, l_rate, n_epoch):
predictions = list()
coef = coefficients_sgd(train, l_rate, n_epoch)
for row in test:
yhat = predict(row, coef)
predictions.append(yhat)
return(predictions)
# Linear Regression on wine quality dataset
seed(1)
# load and prepare data
filename = 'winequality-white.csv'
dataset = load_csv(filename)
for i in range(len(dataset[0])):
str_column_to_float(dataset, i)
# normalize
minmax = dataset_minmax(dataset)
normalize_dataset(dataset, minmax)
# evaluate algorithm
n_folds = 5
l_rate = 0.01
n_epoch = 50
scores = evaluate_algorithm(dataset, linear_regression_sgd, n_folds, l_rate, n_epoch)
print('Scores: %s' % scores)
print('Mean RMSE: %.3f' % (sum(scores)/float(len(scores))))
一个等于 5 的 k 值被用于交叉验证,给每次迭代 4898/5 = 979.6(低于 1000 都行)条记录来进行评估。对一个小实验选择了 0.01 的学习率和 50 训练 epoch.
你可以尝试你自己的配置,看你能否超过我的分数。
运行这个样本,为 5 次交叉验证的每一次 print 一个分数,然后 print 平均均方根误差(RMSE)。我们可以看到(在归一化的数据集上)该 RMSE 为 0.126。如果我们只是预测平均值的话(使用 Zero Rule Algorithm),那么这个结果就低于基准值 0.148。
Scores: [0.12259834231519767, 0.12733924130891316, 0.12610773846663892, 0.1289950071681572, 0.1272180783291014]
Mean RMSE: 0.126
扩展
这里给出了一些扩展练习,你可以思考并尝试解决它们:
-
调整该实例。调整其学习率、epoch 的数量甚至原始数据处理和准备的方法,以期能提高最终结果。
-
批量进行随机梯度下降。改变随机梯度下降算法使其在每个 epoch 上累积更新,且仅在 epoch 结束时批量更新系数。
-
额外的回归问题。应用该技术来解决 UCI 机器学习库中的其它回归问题。
你会探索这些扩展任务吗?