阿布云
你所需要的,不仅仅是一个好用的代理。
Python中代码糟糕的模式

错误代码千千万,在Python中,有一种是最糟糕的。
在其他两位工程师每人花费三天的时间试图去搞定一个Unicode编码的“玄学”问题而徒劳无功后,我仅仅花费了一天时间就定位到了错误的子句,尽管很累,但是很开心。十分钟后,我们就有了应对该bug的方法。
我们本可以用十分钟而不是宝贵的七天来解决这个问题,这样的事实让我们很痛苦。当然,这样说也有点鲁莽……
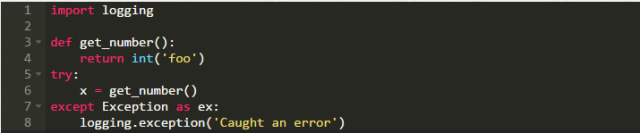
下面的这段代码就是关键点,这一小段代码是Python开发者能够写出来的最具有自我毁灭性的代码片段之一:

这一段代码还有很多其他的写法,如“except Exception:”或者“except Exception as e”,这给后续的工作带来了很大的麻烦:忽略和隐藏了错误的发生,并且不给出任何提示,否则在一般情况下类似的问题是很容易解决的。
为什么我说这段代码是当今Python世界中最可怕的代码呢?
- 人们写这段话是因为知道这里发生某种特定类型的异常,然而,捕获异常后却忽略所有的错误……甚至是那些不可预料的异常。
- 当这个bug出现时——经常出现,因为生产环境中总是有这样的代码——你可能都不知道代码库的哪部分出现了错误。这可能会耗费上好几小时沮丧的时光去才能发现错误竟然是出现在try语句块中。
- 就算你发现了错误,在你想要解决问题时,却发现缺少必要的提示信息。这个错误/异常的类型是什么?涉及到哪些调用和数据接口?错误最开始出现在哪一个文件的哪一行代码?
- 更 糟糕的是,这很有可能伤害到在当前代码上工作的工程师的士气,乐趣甚至是自尊。错误出现时,故障排查人员可能需要花费几个小时去理解代码。他们会觉得自己 是个糟糕的码农,因为他们需要几个小时才能找到错误。事实上并不是。捕获了异常而又对错误放任不管,这样的问题很难定位,排除,修复。
无论是独自工作还是作为团体中一份子,在我作为Python民工的十年开发经历中,这是我遇到的最能够打击士气,降低生产力和应用可靠性的代码片段,如果你有其他更厉害的代码,欢迎讨论。
我们为什么会写出这样的代码?
当然,没有人故意写这样的代码给团队成员增加压力和破坏应用的可靠性。我们之所以写这个是因为在try语句块中,代码在某些特定情况下可能会执行失败。乐观地进行尝试并且捕获异常是解决这种问题的一种很优秀,很Python的做法。
更阴险的是,去捕获异常,然后不报出任何对应的处理并不是这个可怕的想法中最糟糕的时候,然而,当你按下保存按钮时,你就将你的代码处于“万劫不复”的深渊:
- Bugs能够在开发过程中避免被发现地命运,最终会被推送到实际生产环境中。
- 当你发现bug的存在之前,它可能已经存活了数分钟,数小时,数天甚至是数周。
- 这样的bug很难定位。
- 即使你知道哪里会出现异常,你也很难去修复这个bug。
注 意,我并不是说不去捕获异常。有很多必需的理由去捕获异常并进行处理,但就是千万不要让它静悄悄地溜走。比如当你处理一项至关重要的事务时,你甚至不想让 它简单地执行完就算了,比较明智的做法是插入try语句来捕获异常,并把相应的堆栈追踪信息记录使用logging.ERROR记录下来,然后再继续执 行。
解决之道
所以如果你不想捕获范围太宽广的异常,有什么替代的办法呢?有两种选择。
在大多数情况下,最好建议你去捕获更加特定的异常,如:

这是你首先应当做的尝试。它需要你对相关的代码有一些了解,如此才可能推断出会发生什么类型的异常。当你是第一次写自己的代码时,这种方法还是比较简单的。不过当清理别人代码时,这就会让你痛苦万分的。
如 果有些代码需要捕获所有的异常,如在顶层循环中长时间运行的程序,捕获的每个异常需要把相关的堆栈追踪信息写入日志或者文件,同时要有相应的时间戳。如果 你是使用Python的logging模块,做起来时非常简单的,每个logger对象都有叫exception的方法,它接受一个字符串做参数。如果你 在异常捕获的时候调用这个方法,捕获的异常连同堆栈追踪信息都会被自动记录下来。
这个日志包含错误信息,后面几行是堆栈追踪信息。

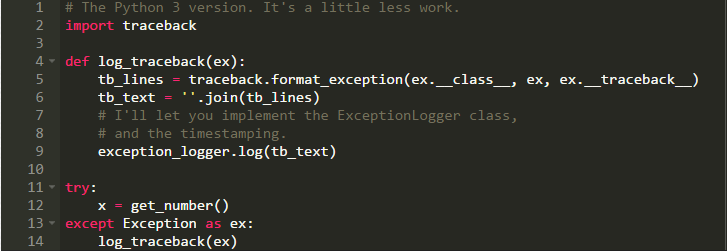
如果你的应用程序并不是使用logging模块来进行记录呢?假设你不想重构你的代码,你仅仅需要找到异常语句,并对堆栈追踪信息进行格式化输出。在Python3里很容易做到的。
在Python2中,你再多做一丢丢工作就好了:因为exception对象没有相对应的堆栈追踪信息。你可以在except语句块中调用sys.exc_info()函数来实现。
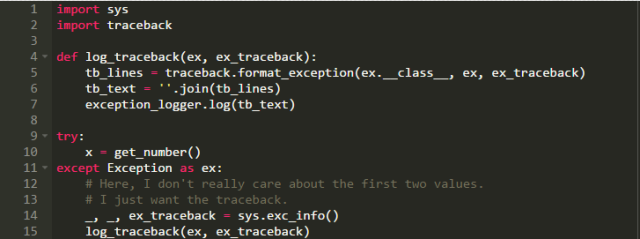
正如你所看到的,你可以把上述两种代码中的traceback-logging函数进行整合,从而可以忽略你是在Python2还是Python3下工作。

挽救措施
“好的吧,Aaron,你成功说服了我。我为我过去做的蠢事而流泪悔恨。我现在能做点什么补救措施?”我很高兴你这样问,下面的一些方法你可以尝试一下。
在你的编程规范中明确地制止它
如果你的团队有代码评审这一环节,你们应该会有代码编写的指导手册。如果没有,也很容易创建——就跟新建一个wiki页面一样。你需要把以下两条建议加入:
- 如果有些代码需要捕获所有的异常,如在顶层中长时间运行的程序语句,那么每个捕获的异常都需要将其相关的堆栈追踪信息记录下来,包括时间戳。不仅仅是异常的类型和信息,也包括整个的追踪信息。
- 对于其他的大多数异常来说,尽可能捕获精确类型的异常,如值错误,连接超时等。
为已经存在的except字句列清单
上面的方法能够帮助你避免未来的错误。然而已经存在的异常捕捉过广的except语句怎么办?很简单:在bug追踪系统中列出 except 字句清单,然后去一个个地修复它们。这是简单且有效的解决问题的办法。你可以现在就着手去做。
我 建议你为每一个仓库或应用去建立清单,在你的代码中找到每个Exception,然后去优化它(你只需要在代码库通过检索找出“except”和 “except Exception”)。你可以把它转换成处理某种特定类型的异常,或者如果你对代码不清楚的话,修改except语句去记录堆栈追踪信息。
你 还可以进一步优化,为需要指定特定类型的异常建立一个清单。如果感到这个异常可以更加精确时,但是你对代码的内部结构不清楚时可以这样做。在这种情况下, 你需要记录该异常的堆栈追踪信息;单独为此创建一个清单来记录;把它委派到某个对代码更加了解的家伙手里。如果你在单个的try/except中花费超过 5分钟的时间去思考找出一个特定的异常时,我推荐你这样做。
培训团队中的其他成员
你是否参加定期的工程会议?一周一次?两周一次?还是一个月一次?你可以讲解这个“反面典型”,讲一下它对团队生产力造成的危害和及其简单的解决办法。
更好的是,你可以直接去找技术负责人或者工程经理来阐述这个问题。因为他们也对团队的生产力很关心。你可以把这篇文章的链接发给他们。如果有需要的话,让我跟他们直接通话来说服他们。
你甚至可以扩展到更广的社区。你是否会参加Python相关的工程师聚会?他们是否有“闪电会谈”这种环节?你是否可以在下次聚会时申请5到15分钟的发言时间?把这个伟大的“福音”传递给他们。
为什么要记录所有的堆栈追踪信息?
在上面的文字中,我一次次说到记录所有的堆栈追踪信息,而不仅仅是异常的信息。这样看起来可能工作量更大一点,你可能会迷失一个个与之相关的模块中。难道仅仅记录信息本身不就够了么?
不, 远远不够。即使是一个经过精心设计的异常信息也只能告诉你异常语句在哪里,在哪个文件的哪一行里。通常来说并没有缩减多少范围。好吧,我们来假设一下最好 的情况,当然,仅仅记录信息也比什么都不记录好,但是它并不会告诉你问题的源头在哪。很有可能出现在一个完全不同的文件或者模块里面,而人工去猜测很难办 到的。
更复杂的是,在真实的开发环境中,团队成员的各种代码都有可能调用抛出异常的语句。也许当Foo类中的bar方法调用时会出现,但函数bar()调用时却不会出现异常。仅仅记录错误信息是无法区分这两者的区别的。
最 近我所经历的事故发生在一个中等规模的开发团队中,大概50人,我是新来的,负责处理近四个月来一直出现的Unicode编码问题。异常被捕获了,消息被 记录了,但是没有其他的信息可供参考。两个资深的工程师已经在这个问题上花费了数日时间,最终放弃了,他们没法找到问题所在。
他们是德高望重的程序员,最终,出于无奈,他们把这个问题交给了我,借助他们先前的经验,我成功复现了问题的发生,并记录下相关的堆栈追踪信息。六个小时之后,我找到了问题所在。一旦我设置了堆栈追踪信息,你知道我用多长时间就解决这个问题了么?
十分钟。仅仅十分钟。一旦我们有了堆栈追踪信息,修复的方法自然就有了。如果能够提早记录堆栈追踪信息,我们本可以节省下一个工程师一周的时间。还记得我前面说过的话么?在你解决问题时,设置堆栈追踪信息与否,解决bug的时间可能是几天或者是几分钟。我可不是开玩笑的。