阿布云
你所需要的,不仅仅是一个好用的代理。
Python对于招聘信息的爬取

自学python的大四狗发现校招招python的屈指可数,全是C++、Java、PHP,但看了下社招岗位还是有的。于是为了更加确定有多少可能找到工作,就用python写了个爬虫爬取招聘信息,数据处理,最后用R语言进行可视化呈现。项目地址: Github Repo 求关注。
scrapy爬虫
python语言简单强大,虽然效率比不上C++这类编程语言,但因为没有了繁琐严格的语法,能让程序员更加专注于业务逻辑,缩短开发周期。虽然用urllib、beautifulsoup之类的包也可以写出爬虫,但是使用scrapy框架能够避免重复制造轮子,可以写尽可能少的代码实现。以下就介绍爬虫核心的代码:
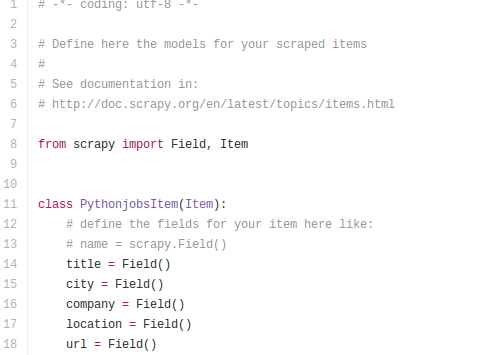
Item
首先需要定义你要爬取的是什么样的数据,在scrapy自动生成的项目文件里的items.py中定义爬取的数据。我爬取了招聘的岗位名称(title)、城市(company)、地址(location)和招聘信息的url:
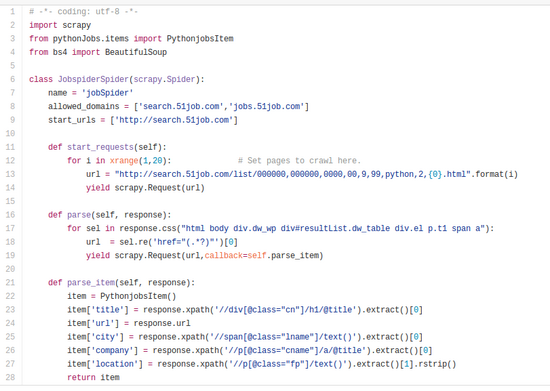
Spider
爬虫自然是主体的逻辑部分,可以用scrapy的genspider子命令生成模板代码,还可以设置spider类型。此处用的最基础的spider.Spider类型。爬取的列表页是51job(51job好爬!)手动搜索全国python招聘信息得到的,通过观察可以发现它翻页是通过url里的参数实现的,因此写了个生成器生成每页对应的request。parse方法则是其实request对应的response默认的处理方法,在此用css选择器(这里应该是用浏览器工具直接生成的,实际应该不需要这么长)和正则表达式抽取出每一条招聘信息的地址,调用Request方法获得response再把response传给parse_item方法(这个方法是自定义的,不是scrapy默认支持的方法)处理。在parse_item方法中的response才是真正的每条招聘信息详情页。这里主要使用xpath选择器,因为不是前端不大熟悉css选择器。xpath和css选择器都可以在w3cschool找到教程,很短很快能看完。
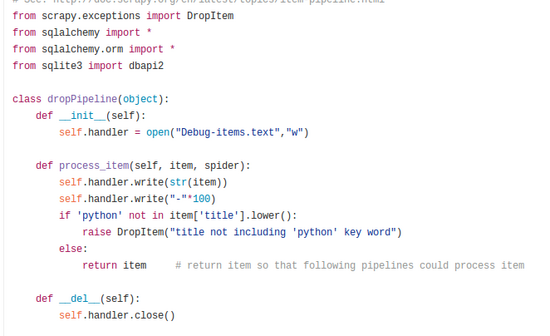
Pipelines
Pipeline管道用于爬取到Item后的数据处理,虽然scrapy本身自带一些存储功能如CSV,但如果要自定义更复杂的处理存储可以在pipeline里实现,最主要是在process_item(self,item,spider)方法中实现。在这实现了两个pipeline,第一个是dropPipeline,用于判断爬取的Item招聘岗位标题中是否有python字串,如果没有就抛出DropItem异常丢弃Item。第二个pipeline实现了sqlite存储。注意在setting里设置好每个管道的顺序,先通过丢弃的管道剩下的再经过存储管道,否则丢弃就没有意义了。
middleware
其实上面代码能实现爬取存储了,不过我写了个没用上的middleware。middleware中间件就是用于处理request和response的,可以在request发出前对其进行处理,response收到后进行处理。写了一个自动切换http代理的中间件,本来想得是http代理从西刺网站抓取(代码仓库里有,用的selenium爬的),但是测试了下其实西刺网站代理很多是不能用的,所以最后干脆不用了~
数据处理
数据处理主要是用高德地图的api获取地理位置坐标,但因为在数据可视化阶段使用的可视化工具是不是国产的,而国内地图的经纬度又经过了加偏处理,所以还需要进一步转换成国际标准的经纬度,幸亏也有api可以用。在这一步还同时统计了每座城市的招聘数量,不过其实这个放最后用R语言统计好像更方便。具体代码就不贴了,太长,可以去github看。
R语言可视化
这个是最后的重头戏,其实R语言不是很精通,在coursera上上的约翰霍普金斯大学的数据科学系列课程,书上没有的干货很多,比如shiny,比如R语言包怎么写,分析报告怎么写,甚至用R写ppt怎么写,还有很多设计的项目可以实践。。。但是要在统计分析方面深入的话还是看书比较好,课上的有点快,特别是统计学那部分一个个概念分分钟扔给你,根本听不懂。。。由于实在没怎么学过统计学,并且爬取的信息也有限,所以这里只进行了可视化。
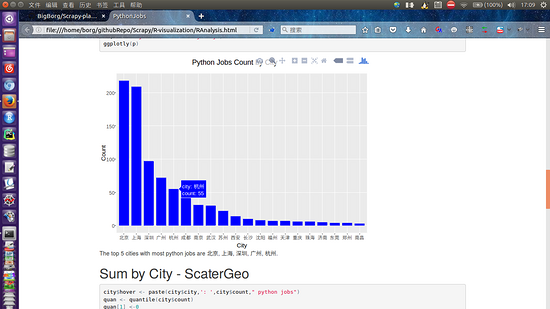
- ggplot可以是R语言可视化最著名的包,下载量也是在所有R语言包中靠前的。而plotly是专门做数据可视化的,支持python、R、Matlab等(还是在公开课干货中看到的)。plotly包只要一个函数(ggplotly)就可以把普通的ggplot转换成可交互的图,可以放大缩小拖拽,鼠标经过时还会显示具体的数据。图中可见北上深广python招聘还是挺多的,北上都有两百多,而到深圳就只有90了,再后面就更少了。还是得去大城市机会比较多~
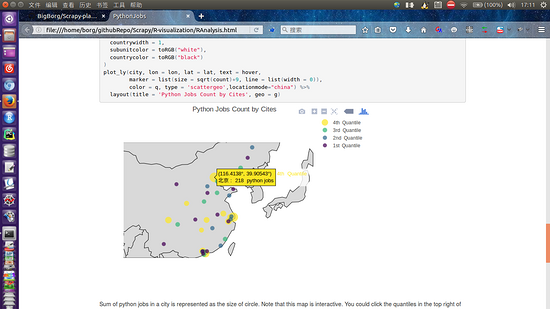
2.plotly的scatergeo图,圆圈大小代表数据大小,经过根号调整过大小,不然差距太大,小圆圈全都被覆盖了。右侧的四分位点击后是可以隐藏或者显示特定颜色的圆圈的。还有鼠标悬停在圆圈上同样会显示详细信息。遗憾的是plotly在亚洲部分的地图还不能细分到省。
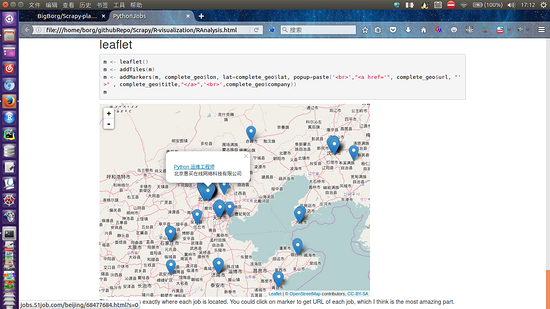
3.leaflet地图则是另一个R语言包,同样是公开课看到的。地图上会显示每一个招聘信息的位置,点击后有职位名称和公司名称,职位名称还是个链接。leaflet地图还是很让人吃惊,竟然不用翻墙而且放大后地点还挺多的。要找离你最近的python招聘用这个图还是真的很不错的!