阿布云
你所需要的,不仅仅是一个好用的代理。
python打造渗透工具集(一)

难易程度:★★★
阅读点:python; web安全 ;
文章作者: xiaoye
文章来源: i春秋
关键字:网络渗透技术
一、信息搜集–py端口扫描小脚本
端口扫描是渗透测试中常用的技术手段,发现敏感端口,尝试弱口令或者默认口令爆破也是常用的手段,之前自学python时候百度着写了个小脚本。
端口扫描小脚本:
#coding: utf-8
import socket
import time
def scan(ip, port):
try:
socket.setdefaulttimeout(3)
s = socket.socket()
s.connect((ip, port))
return True
except:
return
def scanport():
print '作者:xiaoye'.decode('utf-8').encode('gbk')
print '--------------'
print 'blog: [url]http://blog.163.com/sy_butian/blog'[/url]
print '--------------'
ym = raw_input('请输入域名(只对未使用cdn的网站有效):'.decode('utf-8').encode('gbk'))
ips = socket.gethostbyname(ym)
print 'ip: %s' % ips
portlist = [80,8080,3128,8081,9080,1080,21,23,443,69,22,25,110,7001,9090,3389,1521,1158,2100,1433]
starttime = time.time()
for port in portlist:
res = scan(ips, port)
if res :
print 'this port:%s is on' % port
endtime = time.time()
print '本次扫描用了:%s秒'.decode('utf-8').encode('gbk') % (endtime-starttime)
if __name__ == '__main__':
scanport()
对于端口扫描技术,其实分很多种,通常是利用tcp协议的三次握手过程(从网上偷张图。。)
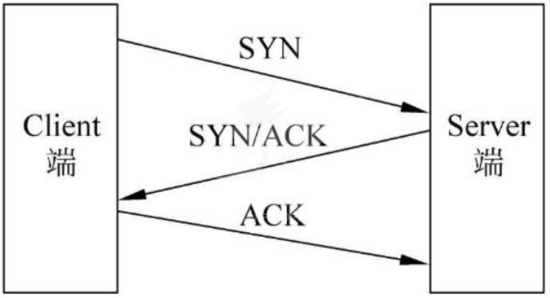
放出的那个脚本,是利用了tcp connect() 即完成了tcp三次握手全连接,根据握手情况判断端口是否开放,这种方式比较准确,但是会在服务器留下大量连接痕迹。
当然,如果不想留下大量痕迹,我们可以在第三次握手过程,将ack确认号变成rst(释放连接),连接没有建立,自然不会有痕迹,但是这种方法需要root权限
好了,先讲解一下我们的py端口扫描小脚本:
核心代码:
portlist = [80,8080,3128,8081,9080,1080,21,23,443,69,22,25,110,7001,9090,3389,1521,1158,2100,1433]
for port in portlist:
res = scan(ips, port)
if res :
print 'this port:%s is on' % port
这段代码是定义了要扫描的端口,并且用for ..in .. 来进行遍历
socket.setdefaulttimeout(3)
s = socket.socket()
s.connect((ip, port))
这段代码,是利用了socket套接字,建立tcp连接,socket.socket()就是s = socket.socket(socket.AF_INET, socket.SOCK_STREAM),用于tcp连接建立
二、实用爆破小脚本–压缩文件密码爆破&&ftp爆破
对于压缩文件,py有自己的处理模块zipfile,关于zipfile的实例用法,在violent python里有实例脚本,模仿书里写了个小脚本
#coding: utf-8
'''
z = zipfile.ZipFile('') , extractall
z.extractall(pwd)
'''
import zipfile
import threading
def zipbp(zfile, pwd):
try:
zfile.extractall(pwd=pwd)
print 'password found : %s' % pwd
except:
return
def main():
zfile = zipfile.ZipFile('xx.zip')
pwdall = open('dict.txt')
for pwda in pwdall.readlines():
pwd = pwda.strip('\n')
t = threading.Thread(target=zipbp, args=(zfile, pwd))
t.start()
#t.join()
if __name__ == '__main__':
main()
其实脚本很简单,核心就一个地方:
zfile = zipfile.ZipFile('xx.zip')
..............
zfile.extractall(pwd=pwd)
ZipFile是zipfile模块重要的一个类,zfile就是类的实例,而extractall(pwd)就是类里的方法,用于处理带有密码的压缩文件;当pwd正确时,压缩文件就打开成功。而此脚本就是利用了zipfile模块的类和方法,加载字典不断尝试pwd,直至返回正确的密码,爆破成功
python在爆破方面也很有优势,比如ftp,py也有ftplib模块来处理,一次ftp连接过程如下:
ftp = ftplib.FTP()
ftp.connect(host, 21, 9)
ftp.login(user, pwd)
ftp.retrlines('LIST')
ftp.quit()
connect(ip, port, timeout)用于建立ftp连接;login(user,pwd)用于登陆ftp;retrlines()用于控制在服务器执行命令的结果的传输模式;quit()方法用于关闭ftp连接
是不是觉得和zipfile的套路很像?没错,你会写一个,就会写另外一个,就会写许许多多的爆破脚本,脚本我就不放出来了,大家自己动手去写一写(p.s:关于ftp爆破,在加载字典之前,请先尝试空密码,即ftp.login(),万一成功了呢。。)
三、目录探测–py低配版御剑
昨天写了个小脚本,用来探测目录,实现和御剑一样的效果,脚本是写好了,开了多线程,但是还算很慢。。之后我会再次修改:
#coding: utf-8
import sys
import requests
import threading
def savetxt(url):
with open('domain.txt', 'a') as f:
url = url + '\n'
f.write(url)
def geturl(url):
r = requests.get(url, timeout=1)
status_code = r.status_code
if status_code == 200:
print url + ' 200 ok'
savetxt(url)
#print url
#print status_code
syslen = len(sys.argv)
#print syslen
#res=[]
url = raw_input('请输入要扫描目录的网站\n'.decode('utf-8').encode('gbk'))
for i in range(1,syslen):
with open(sys.argv[i], 'r') as f:
for fi in f.readlines():
fi = fi.strip('\n')
#print fi
fi = url + '/' + fi
#print fi
t = threading.Thread(target=geturl, args=(fi,))
t.start()
t.join()
#res = ''.join(res)
#print res
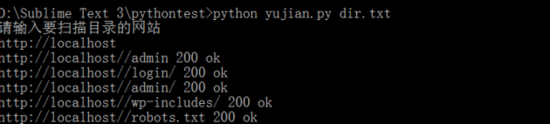
能run起来,速度较慢。。
说一下主要思想吧,之后我改完再细讲。。:
加载1个或者多个字典,将字典中的内容与输入的url进行拼接得到完整url;
关于加载多个字典,代码实现如下:
syslen = len(sys.argv)
#print syslen
#res=[]
url = raw_input('请输入要扫描目录的网站\n'.decode('utf-8').encode('gbk'))
for i in range(1,syslen):
with open(sys.argv[i], 'r') as f:
for fi in f.readlines():
fi = fi.strip('\n')
#print fi
fi = url + '/' + fi
利用sys.argv,我们输入python yujian.py dir.txt就加载dir.txt,输入dir.txt php.txt ,因为有for i in range(1,syslen):,syslen=3,range(1,3)返回[1,2];
with open(sys.argv , ‘r’) as f: 它就会自动加载输入的两个txt文件(sys.argv[1]、sys.argv[2]);也就是说,我们输入几个文件,它就加载几个文件作为字典
当我们遇到php站点时,完全可以把御剑的字典拿过来,只加载php.txt dir.txt,这点和御剑是一样的:
通过python的requests.get(url)的状态返回码status_code来对是否存在该url进行判断;
如果返回200就将该url打印出来,并且存进txt文本里
目前是这么个想法。。
———————————————————————–
更新:多线程加队列目录探测脚本 : https://github.com/xiaoyecent/scan_dir
有关于更多小脚本, 可以访问 https://github.com/xiaoyecent 目前添加了百度url采集、代理ip采集验证、爬虫、简单探测网段存活主机等小脚本,新手单纯交流学习,大牛勿喷